Understanding ISTA as a Fixed-Point Iteration
Background: Sparse Coding and Basis Pursuit Denoising
Sparse coding is an area of signal processing concerned with finding the representation of a signal with respect to a dictionary of vectors or atoms with the fewest number of coefficients. The assumption is that in some transform domains a signal ought to have only a few non-zero coefficients. Some simple examples of sparsity with respect to certain transforms are:
complex sine-waves in the Fourier domain
natural images in the DCT and Wavelet coefficient domains
Clearly sparsity is not a bad prior for many classes of signals. With redundant/over-complete dictionaries we can expect even greater sparsity in representation as the atom diversity can bring us closer to our signal in fewer combinations. This is similar to how the redundancy in human languages (synonyms etc.) allows ideas to be expressed very concisely.
Compression tasks and inverse problems (denoising, in-painting, deblurring, etc.) can benefit from sparse-coding in a redundant dictionary. Basis Pursuit DeNoising (BPDN) is one characterization of the sparse-coding objective in which we seek to minimize the taxi-cab norm of our transform coefficients as a convex-surrogate to the counting-norm (pseudo-norm). The BPDN objective can be written as
where is our signal, is our dictionary, is our sparse-representation or sparse-code, and is a Lagrange multiplier term that balances the data-fidelity term and code sparsity.
The Iterative Soft-Thresholding Algorithm (ISTA)
Today, ISTA is by no means the best solution for solving the BPDN problem. However, it is very simple, easy to implement, and a good starting point for understanding this realm of optimization.
In its most common form, ISTA is written as,
Input: . Initialize: .
While not converged, repeat: return
where is the soft-thresholding operator with cutoff parameter . We'll now walk through deriving ISTA by first deriving the Proximal Gradient Method – a fixed-point iteration – and then showing how ISTA is a special case.
Fixed-Point Iterations
Fixed point iterations (FPIs) can in general be characterized as repeating
for function . The contractive mapping theorem guarantees that this iterate will converge to the unique fixed point of given that is a contractive mapping (more on this next section).
For the purposes of optimization of a differentiable function , we can exploit the FPI structure by rewriting as . As at the extrema of they are all fixed points of . If is contractive, we can arrive at it's minima or maxima by a FPI on .
Newton's Method does exactly this by replacing with the Jacobian of at . The Gradient Descent algorithm does so with , a learning rate set by the user before starting (which must be chosen carefully so as to not diverge).
Contractive Mappings
A mapping is called Lipschitz continuous if there exists a constant such that
and is further called a contractive mapping if the Lipschitz constant . Intuitively we see that a contractive map is one where the distance between points becomes closer upon application, and that such a map could eventually bring us to a point that maps to itself (upon repeated application).
The Lipschitz constant will be brought up often in the discussion of ISTA. When known, it can be used to ensure that a function is contractive by scaling said function by !
Proximal Operators and The Proximal Gradient Method
The area of proximal algorithms is built off of a nice mathematical object called the proximal operator, defined as
with parameter for functional .
A nice property of this operator is that minimizes the functional if and only if it is a fixed point of , i.e., .
Derivation of the Proximal Operator for the -Norm
As an example, let's derive the proximal operator for ,
To find the minimum of we differentiate element-wise with respect to and set the result equal to zero,
This corresponds to the following graph,
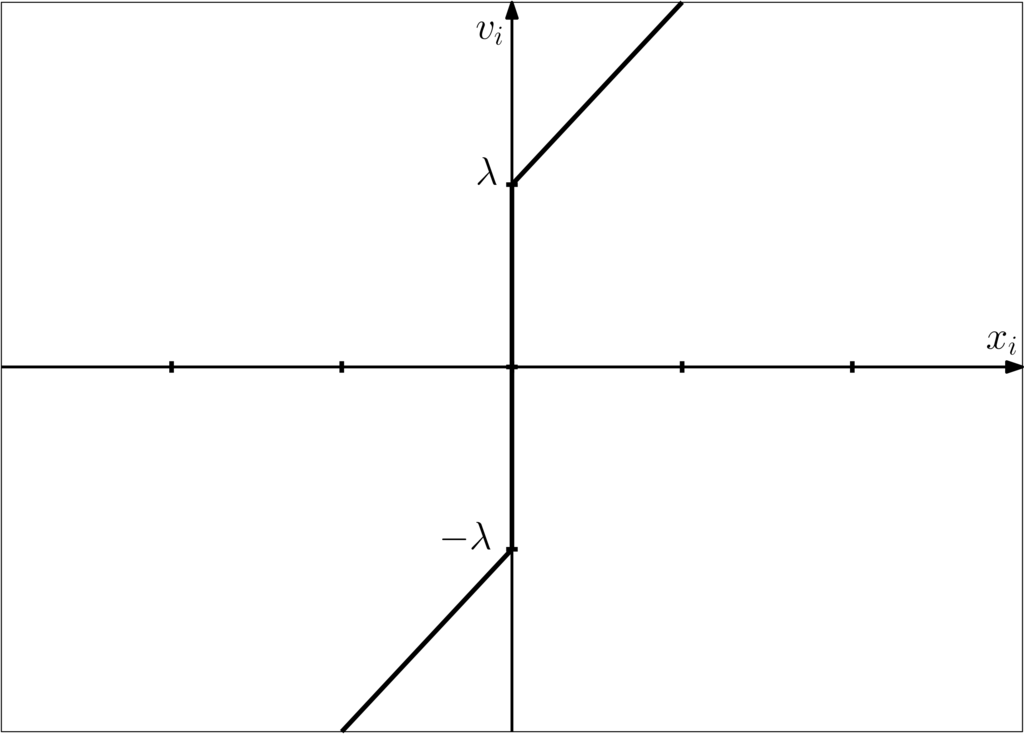
Either algebraically or graphically we may then obtain the following piecewise representation for in terms of ,
This corresponds to the element-wise soft-thresholding operator, , shown below.
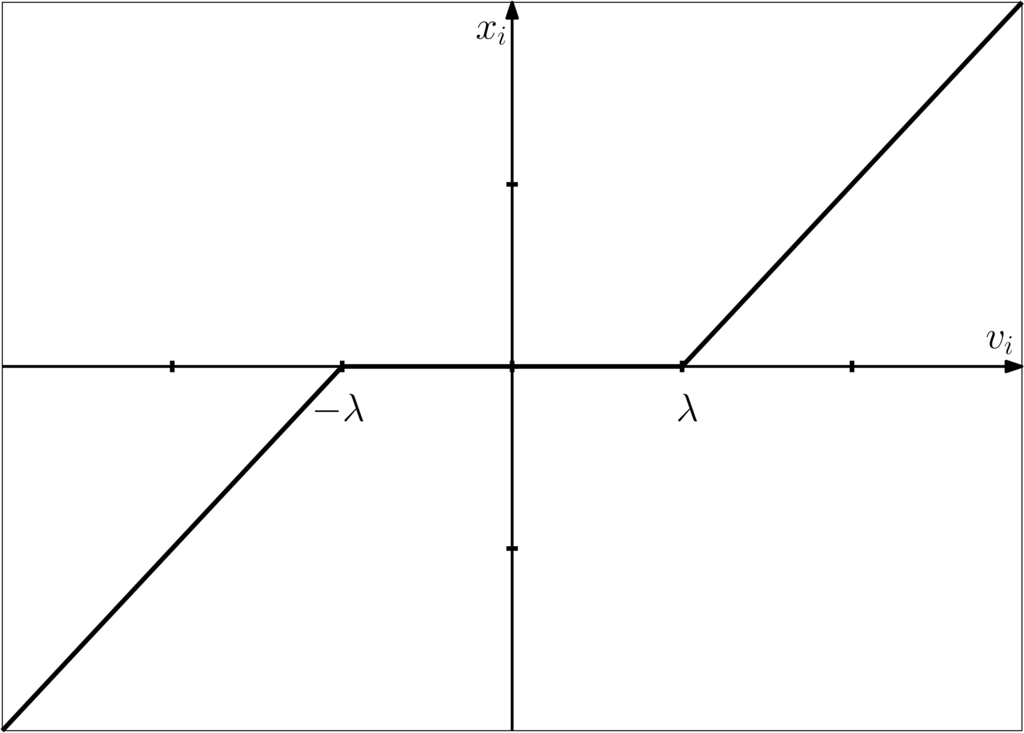
The soft-thresholding operator may be written more compactly as
or in Deep-Learning notation as
Thus we have derived the proximal operator for the vector-norm to be the element-wise soft-thresholding operator (also known as the shrinkage-thresholding operator).
The Subdifferential
In order to continue our derivation of ISTA it is helpful for us to look at the proximal operator from a different perspective. First recall that the subdifferential of convex function at point is the set defined as
i.e., the set of slopes for which the hyperplanes at remain below the function. This allows us to generalize the idea of derivatives to convex functions that are non-smooth (not differentiable everywhere).
For instance, we know that a differentiable convex function has a global minimum at if and only if its gradient is zero, . Similarly this is the case for a non-smooth convex function if and only if zero is in the subdifferential, . Note that the subdifferential is equal to the gradient at a differentiable point.
Example:
is the global minimizer of as
Resolvent of the Subdifferential
Theorem: With some restrictions on convex function , the proximal operator is related to the subdifferential by
The inverse set-relation is referred to as the resolvent of the subdifferential.
Proof Boyd (3.4): Consider . Then,
Note that this shows that the set-relation for convex is single-valued, as the proximal operator is a single-valued function.
The Proximal Gradient Method
Armed with our understanding of the proximal operator, the subdifferential, and the prox-op's characterization as the resolvent of the subdifferential, we can continue on our journey to derive ISTA by deriving The Proximal Gradient Method (Boyd Sec 4.2.1).
First, we will state the method. Consider the following optimization problem:
with both convex functionals and differentiable. The proximal gradient method
is a fixed point iteration that converges to the unique minimizer of the objective function for a fixed step-size , where is the Lipschitz constant of . It can be shown that the algorithm converges as – very slow!
This can be seen from the necessary and sufficient condition that is a minimizer of if and only if zero is in its subdifferential,
We've used the fact that the proximal operator is the resolvent of the subdifferential to move from the containment relation to one of equality. The operator
is referred to as the forward-backward operator. The proximal gradient method as shown applies the forward-backward operator in a fixed-point iteration to minimize .
ISTA Assembled
We're now ready to assemble the Iterative Soft-Thresholding Algorithm. We'll restate the objective for convenience,
where , i.e. a fat/over-complete dictionary, is our signal, and is our sparse code to be determined.
If we label the quadratic term as and the relaxed sparsity term as , we can use the proximal gradient method to get the update step
where is the proximal operator for the norm, soft-thresholding with parameter , as derived earlier.
More often, the ISTA update step is presented as
where , the square of the maximum singular value of , i.e. the largest eigen-value of and Lipschitz constant of . This is simply ISTA with its fixed maximum step-size, ensuring that in turn are contractive.
In sum, ISTA is a fixed-point iteration on the forward-backward operator defined by the soft-thresholding (prox-op of the norm) and the gradient of the quadratic difference between the original signal and its sparse-code reconstruction. The threshold and step-size of the algorithm are determined by the sparsity-fidelity trade-off required by the problem and the maximum scaling possible in the dictionary.
Going Further
Can we train an Artificial Neural Network to do ISTA faster? (Yes!) – LISTA
Why are we still talking about ISTA when other algorithms do better?! – ADMM
Why has the Relu appeared outside of a Deep-Learning context? – Elad